Stardog Similarity Model
In the previous section I was able find similar files by searching for terms extracted from their comment headers and by visualizing how files are connected by common terms. Finding similar entities in the graph is usually much more complex than these simple examples. This is where machine learning models could be helpfule.
The Stardog database provides an easy way to specify and use such machine learning models, as described in this blog post. The basic steps are to :
- Create a Similarity Model.
- Execute a Similarity Query based on the model.
1. Create the Similarity Model
The model for this project is very basic. I want to find files that are similar to a file I have identified. I created a model where terms are used to predict files. The model is inserted into the database by executing the code:
PREFIX spa: <tag:stardog:api:analytics:>
PREFIX filecat: <https://www.example.org/tw/filecat#>
# Predict file based on terms
INSERT {
graph spa:model {
:simModel a spa:SimilarityModel ;
spa:arguments (?terms) ; # Use terms to
spa:predict ?file . # predict file name
}
}
WHERE {
SELECT (spa:set(?term) as ?terms) ?file {
?file filecat:hasTerm ?term .
}
GROUP BY ?file
}
2. Similarity Query
With both the model and instance data in the database it is possible to find similar files based on terms. I want to find files similar to 01-FileCatMain.R, which I know from a separate query has the unique IRI filecat:FILE_b7afd304 . I limit the query to predict the top three matches ( limit 3) and sort by descending confidence:
PREFIX filecat: <https://www.example.org/tw/filecat#>
PREFIX spa: <tag:stardog:api:analytics:>
SELECT ?similarFileName ?confidence
WHERE {
graph spa:model {
:simModel spa:arguments (?terms) ;
spa:confidence ?confidence ;
spa:parameters [ spa:limit 3] ; # Select the top 3
spa:predict ?similarFile .
}
{ ?similarFile filecat:fileName ?similarFileName }
{
SELECT (spa:set(?term) as ?terms) ?file
{
?file filecat:hasTerm ?term .
VALUES ?file { filecat:FILE_b7afd304 }
}
GROUP BY ?file
}
} ORDER BY DESC(?confidence)
The best match is the 100% confidence value for the specified file matched to itself, which at least hints that the model may be working. The next two matches are of interest.
similarFileName confidence 01-FileCatMain.R 1.0 02-Dictionary.R 0.5853694070049636 03-FileCatTTL.R 0.502518907629606
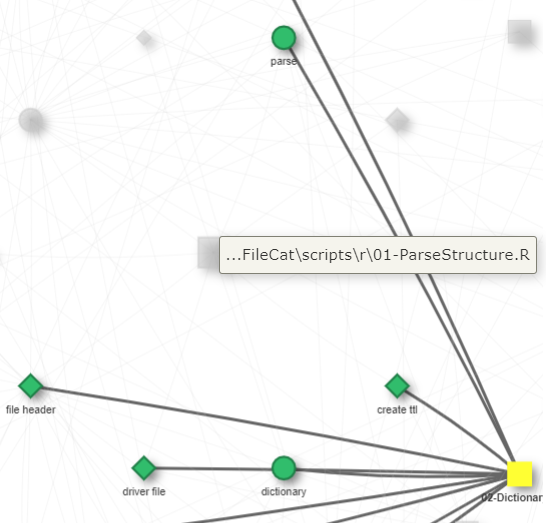
The result is not a surprise. Revisiting the terms visualization for 01-FileCatMain.R, the file 02-Dictionary.R has five terms in common with 01-FileCatMain.R : parse, create ttl, file header, driver file, and dictionary.
NEXT: 7. Conclusion